Far too often I have seen datasets just dumped into one massive S3 bucket, and left for someone else to tidy up later, however with a little consideration, and empathy for those dealing with this in the future, we can do better than this.
Start By Asking a few questions
When I am planning to store a dataset in s3 I typically ask a few questions, one thing to note is I am focused on the semantics of the data, and the business, not just the bucket(s) technical configuration at this stage.
What will consume this information?
What I am trying to understand here is whether this dataset has any known consumers, with the AWS logs example, this may be an ingestion tool like Splunk, which is easier to integrate with if there are a few aggregate buckets.
For datasets which are exported from other systems, or transformed for use in an application, or with an integration it may be easier to combine them into one bucket, especially if other factors I cover in the next few questions aren’t a concern.
As you will see in my following questions, this is a trade off, and I would also review other points below to determine which is the best approach in the long run.
What is the classification for the data?
My goal here is to consider the sensitivity of the data, and how it could affect who is granted access.
Keeping sensitive datasets isolated in their own bucket makes it easier to add controls, and simplifies auditing as there is only one top level identifier, i.e., the bucket name.
One thing to avoid is mixing different data classifications in one bucket, as you then need to tag all data in that bucket at the highest classification, which could complicate granting access to the data.
For an example of data classifications, this is a five-tiered commercial data classification approach provided in this book CISSP Security Management and Practices:
- Sensitive
- Confidential
- Private
- Proprietary
- Public
These classifications would be assigned to a tag, such named Classification on your bucket, for more on this see Categorizing your storage using tags.
In general I recommend keeping different classifications of data separated, for example having raw data and anonymised, or cleaned data in the same bucket is not a good idea.
What are the cost implications for keeping this dataset?
The aim with this question is to understand how cost will be managed for a dataset, there are a couple of factors here, the size of the data, and how much churn will occur for the dataset, either in the form of reads or updates to the data.
For datasets which grow quickly, it may be easier to isolate them in their own bucket, as reporting cost for this dataset is easier, and cost control mechanisms such as lifecycle policies, or disabling/enabling versioning simpler to apply.
For more information on optimising storage costs, see Optimizing costs for Amazon S3.
What is the likely growth of this dataset in 6 to 12 months?
This question is related to the previous cost question, but I am trying to understand how challenging the dataset will be to handle over time. External factors such as traffic spikes for log datasets, which are often outside your control, should be taken into consideration as well.
There are two dimensions to this, the size of the data, and the number of objects in the dataset, both can have an impact on how difficult to wrangle the dataset will be in the future, and how much it will cost to move, or backup.
For more information on how to monitor and manage dataset growth in Amazon S3 I recommend digging into Amazon S3 Storage Lens.
Summary
As a general rule, I would recommend keeping datasets in separate buckets, with each bucket containing data of a single classification, and ideally a single purpose. This will help to simplify cost control, and make it easier to manage the data in the future.
Getting things right from the start will enable you to make the most of your datasets, which is a potential differentiator for your business in this new era of cloud computing, data engineering and AI.
]]>If your using AWS_IAM authentication on an API Gateway, then make sure you set the default authorizer for all API resources. This will avoid accidental exposing an API if you mis-configure, or omit an authentication method for an API resource as the default is None.
In addition to this there is a way to apply a resource policy to an API Gateway, which will enforce a specific iam access check on all API requests. Combining the override to default authorizer, and the resource policy allows us to apply multiply layers of protection to our API, allowing us to follow the principle of defense in depth.
So to summarise, to protect your API with IAM authentication is as follows:
- Enable a default authorizer method on the API Gateway resource.
- Enable an authentication method on the API.
- Assign an API resource policy which requires IAM authentication to access the API.
Doing this with AWS SAM is fairly straight forward, to read more about it see the SAM ApiAuth documentation.
AthenaWorkflowApi:
Type: AWS::Serverless::Api
Properties:
...
Auth:
# Specify a default authorizer for the API Gateway API to protect against missing configuration
DefaultAuthorizer: AWS_IAM
# Configure Resource Policy for all methods and paths on an API as an extra layer of protection
ResourcePolicy:
# The AWS accounts to allow
AwsAccountWhitelist:
- !Ref AWS::AccountId
Through the magic of AWS SAM this results in a resource policy which looks like the following, this results in all the API methods being protected and only accessible by users authenticated to this account, and only where they are granted access via an IAM policy.
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:root"
},
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:us-west-2:123456789012:abc123abc1/Prod/POST/athena/run_s3_query_template"
},
{
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::123456789012:root"
},
"Action": "execute-api:Invoke",
"Resource": "arn:aws:execute-api:us-west-2:123456789012:abc123abc1/Prod/POST/athena/run_query_template"
}
]
}
I typically use an openapi spec to define the API, using the extensions provided by AWS such as x-amazon-apigateway-auth to define the authorisation.
With the default authentication set to AWS_IAM hitting an API which is missing x-amazon-apigateway-auth using curl returns the following error.
{"message":"Missing Authentication Token"}
With default authentication disabled, and the resource policy enabled the API returns the following error, which illustrates the principle of defense in depth.
{"Message":"User: anonymous is not authorized to perform: execute-api:Invoke on resource: arn:aws:execute-api:us-east-1:********9012:abc123abc1/Prod/POST/athena/run_query_template"}
go1.x runtime on Lambda, this is currently scheduled for December 31, 2023. Customers need to migrate their Go based lambda functions to the al2.provided runtime, which uses Amazon Linux 2 as the execution environment. I think this is a bad thing for a couple of reasons:
- There is no automated migration path from existing Go Lambda functions to the new custom runtime. Customers will need to manually refactor and migrate each function to this new runtime, which this is time-consuming and error-prone.
- This will remove
Go1.xname from the lambda console, Go will now just be another “custom” runtime instead of a first class supported language. This makes Go development on Lambda seem less official/supported compared to other languages like Node, Python, Java etc.
Case in point, try searching for “al2.provided lambda” on Google and see how little documentation comes up compared to “go1.x lambda”. The migration essentially removes the branding and discoverability of Go as a Lambda language, I am sure this will improve over time, but it is still ambiguous.
There are articles on the advantages of the al2.provided runtime, including how to migrate functions over to it, such as https://www.capitalone.com/tech/cloud/custom-runtimes-for-go-based-lambda-functions/.
Why is this hard?
The main reason migrating Go Lambda functions to the new runtime is difficult is because:
- Unlike the runtime provided for other languages, the custom runtime doesn’t use the
Handlerparameter to determine the function entry point, this value is ignored, but still required. This is a subtle difference can cause issues if developers are unaware or don’t read the documentation closely. - The lambda service doesn’t check if the bootstrap entry point exists in the archive, so customers may deploy broken functions if they don’t validate this. Sadly, this is NOT very intuitive, and often leads to confusion and errors.
Note: As pointed out by @Aidan W Steele some deployment tools upload empty archives, then later replace them with an updated archive containing the deployed code, so this could be problematic.
For those interested in what the error looks like if you’re missing the bootstrap file, it will return:
{"errorType":"Runtime.InvalidEntrypoint","errorMessage":"RequestId: d604d105-51be-49ce-8457-eee1641398eb Error: Couldn't find valid bootstrap(s): [/var/task/bootstrap /opt/bootstrap]"}
If you see this, you need to validate your deployment package contains the required bootstrap file in the root of the zip archive.
Why is removing Go 1.x a bad idea?
There will be no Go Lambda runtime available after this date, this will be more of an issue for developers who have never used AWS and expect lambda to have a Go runtime available out of the box. This is a change that will require some education and guidance for new developers.
Some of the drawbacks of this are:
- You won’t be able to see Go functions directly in the Lambda console anymore. Go will just be another “custom” runtime instead of a first class supported language like Node, Python, Java etc. This makes Go development on Lambda seem less official/supported.
- Developers will find samples or projects using the old Go 1.x runtime that no longer work out of the box. This will lead to confusion as they try to migrate those functions over to the new runtime.
- Listing lambda functions by runtime used will no longer show “Go1.x” making it less clear if a function was written for Go or another language like Rust or Nim that also use the custom runtime.
- Finding code samples for Go lambda functions on GitHub or tutorials will need to specify if they are using the old or new runtime. A lot of existing content will be outdated immediately.
What can AWS do better?
So what could AWS do to mitigate some of these issues? Here are a few suggestions:
- Provide an updated
go1.al2, which would match the pattern of Java updatejava8.al2runtime announced a few years ago. This updated runtime would use the same entry point convention as the other languages like Node, Python etc and retain the existing user experience, avoiding the hard codedbootstrapfile which is not very intuitive. - Add validation to the deployment process to check for the required bootstrap file, and prevent deployment of invalid archives. This would avoid broken functions being deployed.
I am disappointed that AWS did not invest a bit more time in listening to customers around the usability of the al2.provided runtime. Customers are used to compiling applications to a binary with a descriptive name, then deploying that binary to AWS, having to output a specific file called bootstrap is not very intuitive or discoverable.
Examples
To illustrate the differences I have included some examples, hopefully this helps those not familiar with lambda see the challenges.
Building
This is an example compile command for go based function prior to migration, this will build all commands using the name of the directory as their binary name, then zip up all the binaries with a name ending in -lambda.
build:
CGO_ENABLED=0 GOOS=linux GOARCH=amd64 go build -ldflags="-s -w" -trimpath -o dist ./cmd/...
archive:
cd dist && zip -X -9 ./deploy.zip *-lambda
With this migration, developers will need to package each of their functions to include a bootstrap file, and upload each archive to s3 individually rather than zipping multiple binaries together.
Deployment Configuration Examples
This is an example sam template for a go based function prior to migration:
ExampleFunction:
Type: AWS::Serverless::Function
Properties:
Runtime: go1.x
# this is a example archive containing one or more go binary files
CodeUri: ../../dist/deploy.zip
# note example is the name of the compiled go binary file
Handler: example-lambda
This is an example sam template for a go based function after migration:
ExampleFunction:
Type: AWS::Serverless::Function
Properties:
Runtime: provided.al2
# example archive which must contain a file named bootstrap,
# which is not referenced or checked during deploy.
CodeUri: ../../dist/example_Linux_arm64.zip
# unused by this runtime but still required and can
# cause some confusion with developers if not aware
Handler: nope
Closing Thoughts
While the custom runtime provides better performance, and an updated operating system, the change will require effort for many Go developers on AWS Lambda. Some automated assistance and validation from AWS could help reduce friction and issues from this change.
Personally I am sad to see AWS lambda remove Go as a first class language, as an early adopter of serverless it felt great to have Go supported out of the box. I will miss seeing the gopher logo when browsing functions! 😞🪦
Overall, I think this will negatively the adoption of Go in AWS lambda, at least in the short term, as a lot of developers will find the custom runtime requirements unfamiliar and confusing compared to other runtimes.
As is often the case, new developers will likely struggle most with the provided.al2, then most likely give up and use another language instead of taking the time to understand the custom runtime complexities.
What are your thoughts on the migration and how AWS could improve the experience?
Updates
Thanks to @Aidan W Steele for the feedback on my go2.x suggestion with a much better one of go1.al2 which would match the pattern of java8.al2, and reminder of the various empty zip file shenanigans used in some deployment tools.
What is the problem with IAM User Credentials?
- IAM User Credentials are long lived, meaning once compromised they allow access for a long time
- They are static, so if leaked it is difficult to revoke access immediately
But there are better alternatives, the one I recommend is OpenID Connect (OIDC), which if you dig deep into the Terraform Cloud docs is a supported approach. This has a few benefits:
- Credentials are dynamically created for each run, so if one set is compromised it does not affect other runs.
- When Terraform Cloud authenticates with AWS using OIDC it will pass information about the project and run, so you can enforce IAM policies based on this context.
- Credentials are short lived, expiring after the Terraform run completes.
- You can immediately revoke access by removing the OIDC provider from AWS.
- You don’t need to export credentials from AWS and manage their rotation.
Overall this allows for a more secure and scalable approach to integrating Terraform Cloud with AWS. If you are just starting out, I would recommend setting up OpenID Connect integration instead of using IAM credentials.
AWS Deployment
To setup the resources on the AWS side required to link AWS to Terraform Cloud we need to deploy some resources, in my case I am using a Cloudformation Template which deploy manually. You can find the source code to this template in my GitHub Repo along with a Terraform example to deploy the resources.
Using the Cloudformation template as the example for this post, it creates:
- IAM Role, which assumed by Terraform Cloud when deploying
- Open ID Connect Provider, which is used to connect Terraform Cloud to AWS
The Terraform Deployment role is as follows:
TerraformDeploymentRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Statement:
- Effect: Allow
Action: sts:AssumeRoleWithWebIdentity
Principal:
Federated: !Ref TerraformOIDCProvider
Condition:
StringEquals:
app.terraform.io:aud: "aws.workload.identity"
StringLike:
app.terraform.io:sub: !Sub organization:${OrganizationName}:project:${ProjectName}:workspace:${WorkspaceName}:run_phase:*
Note:
- The IAM role allows Terraform Cloud to assume the role using the OIDC provider, and limits it to the given organization, project and workspace names.
- The policy attached to this role, in my example, only allows Terraform to list s3 buckets; you should customise this based on your needs.
The Open ID Connect Provider is created as follows:
TerraformOIDCProvider:
Type: AWS::IAM::OIDCProvider
Properties:
Url: https://app.terraform.io
ClientIdList:
- aws.workload.identity
ThumbprintList:
- 9e99a48a9960b14926bb7f3b02e22da2b0ab7280
Once deployed this template will provide two outputs:
- The role ARN for the Terraform Deployment role.
- An Optional Audience value, this is only needed if you want to customise this value.
Terraform Cloud Configuration
You’ll need to set a couple of environment variables in your Terraform Cloud workspace in order to authenticate with AWS using OIDC. You can set these as workspace variables, or if you’d like to share one AWS role across multiple workspaces, you can use a variable set.
| Variable | Value |
|---|---|
| TFC_AWS_PROVIDER_AUTH | true |
| TFC_AWS_RUN_ROLE_ARN | The role ARN from the cloudformation stack outputs |
| TFC_AWS_WORKLOAD_IDENTITY_AUDIENCE | The optional audience value from the stack outputs. Defaults to aws.workload.identity. |
Note for more advanced configuration options please refer to Terraform Cloud - Dynamic Credentials with the AWS Provider.
That is it, your now ready to run plans in your Terraform Cloud workspace!
Auditing
Once you have setup both side of this solution you should be able to see events in AWS CloudTrail, filter by service sts.amazonaws.com and look at the AssumeRoleWithWebIdentity events. Each event will contain a record of the Terraform Cloud run, and the name of the project and workspace.
This is a cut down cloudtrail event showing the key information:
{
"userIdentity": {
"type": "WebIdentityUser",
"principalId": "arn:aws:iam::12121212121212:oidc-provider/app.terraform.io:aws.workload.identity:organization:test-organization:project:Default Project:workspace:test-terraform-cloud:run_phase:plan",
"userName": "organization:test-organization:project:Default Project:workspace:test-terraform-cloud:run_phase:plan",
"identityProvider": "arn:aws:iam::12121212121212:oidc-provider/app.terraform.io"
},
"eventTime": "2023-07-18T00:08:34Z",
"eventSource": "sts.amazonaws.com",
"eventName": "AssumeRoleWithWebIdentity",
"awsRegion": "ap-southeast-2",
"sourceIPAddress": "x.x.x.x",
"userAgent": "APN/1.0 HashiCorp/1.0 Terraform/1.5.2 (+https://www.terraform.io) terraform-provider-aws/5.7.0 (+https://registry.terraform.io/providers/hashicorp/aws) aws-sdk-go-v2/1.18.1 os/linux lang/go/1.20.5 md/GOOS/linux md/GOARCH/amd64 api/sts/1.19.2",
"requestParameters": {
"roleArn": "arn:aws:iam::12121212121212:role/terraform-cloud-oidc-acces-TerraformDeploymentRole-NOPE",
"roleSessionName": "terraform-run-abc123"
},
"responseElements": {
"subjectFromWebIdentityToken": "organization:test-organization:project:Default Project:workspace:test-terraform-cloud:run_phase:plan",
"assumedRoleUser": {
"assumedRoleId": "CDE456:terraform-run-abc123",
"arn": "arn:aws:sts::12121212121212:assumed-role/terraform-cloud-oidc-acces-TerraformDeploymentRole-NOPE/terraform-run-abc123"
},
"provider": "arn:aws:iam::12121212121212:oidc-provider/app.terraform.io",
"audience": "aws.workload.identity"
},
"readOnly": true,
"eventType": "AwsApiCall",
"recipientAccountId": "12121212121212"
}
Links
- How to get rid of AWS access keys - Part 1: The easy wins
- Terraform Cloud - Dynamic Credentials with the AWS Provider
- AWS Partner Network (APN) Blog - Simplify and Secure Terraform Workflows on AWS with Dynamic Provider Credentials
So instead of using IAM User credentials, this approach uses IAM Roles and OpenID Connect to dynamically assign credentials to Terraform Cloud runs which is a big win from a security perspective!
]]>So firstly what does automated security remediation for a cloud service do?
This is software which detects threats, more specifically misconfigurations of services, and automatically remediates problems.
How does automated security remediation work?
Typically, security remediation tools take a feed of events from a service such as AWS CloudTrail (audit logging service) and checks the configuration of the resources being modified. This is typically paired with regular scheduled scans to ensure nothing is missed in the case of dropped or missing events.
Can you use IAM to avoid security misconfigurations in the first place?
Cloud services, such as AWS, have fairly complex AWS Identity and Access Management (IAM) services which provide course grained security policy language called IAM policies. These policies are hard to fine tune for the myriad of security misconfigurations deployed by the people working on in these cloud services.
Everyone has seen something like the following administrator policy allowing all permissions for administrators of an AWS environments, this is fine for a “sandbox” learning account, but is far too permissive for production accounts.
Version: "2012-10-17"
Statement:
- Sid: AdminAccess
Effect: Allow
Action: '*'
Resource: '*'
That said, authoring IAM policies following the least privilege to cover current requirements, new services coming online and keeping up with emerging threats can be a significant cost in time and resources, and like at some point provide diminishing returns.
Can you use AWS service control polices (SCP) to avoid security misconfigurations?
In AWS there is another way to deny specific operations, this comes in the for of service control policies (SCP). These policies are a part of AWS Organizations and provide another layer of control above an account’s IAM policies, allowing administrators to target specific operations and protect common resources. Again, these are also very complex to configure and maintain, as they use the same course grained security layer.
Below is an example SCP which prevents any VPC that doesn’t already have internet access from getting it.
Version: '2012-10-17'
Statement:
- Effect: Deny
Action:
- ec2:AttachInternetGateway
- ec2:CreateInternetGateway
- ec2:CreateEgressOnlyInternetGateway
- ec2:CreateVpcPeeringConnection
- ec2:AcceptVpcPeeringConnection
- globalaccelerator:Create*
- globalaccelerator:Update*
Resource: "*"
Investment in SCPs is important for higher level controls, such as disabling the modification of security services such as Amazon GuardDuty, AWS Config and AWS CloudTrail as changes to these services may result in data loss. That said, SCPs are still dependent on IAMs course grained policy language, which in turn is limited by the service’s integration with IAM.
A note about SCPs, often you will see exclusions for roles which enable administrators, or continuous integration and delivery (CI\CD) systems to bypass these policies. These should be used for exceptional situations, for example bootstrapping of services, or incidents. So, using these roles should be gated via some sort incident response process.
So why does automated security remediation exist?
Given the complexity of managing fine-grained security policies, organizations implement a more reactive solution, which is often in the form of automated security remediation services.
What are some of disadvantages of these automated security remediation tools?
- False positives and false negatives: They may generate false positives, where legitimate actions are flagged as security threats, or false negatives, where actual security issues are missed.
- Over-reliance on automation: Organizations may become over-reliant on tools, potentially leading to complacency or a lack of human oversight, which can create new risks and vulnerabilities.
- Limited scope: They may not be able to detect or remediate all types of security issues or vulnerabilities, especially those that are highly complex or require a more nuanced approach.
- Compliance and regulatory issues: Some compliance and regulatory frameworks may require manual security review or approval for certain types of security incidents, which can be challenging to reconcile with automated processes.
- Cultural resistance: Some organizations may experience cultural resistance to automated remediation, as it may be perceived as a threat to job security or the role of security professionals.
- Delayed or dropped trigger events: Automated remediation typically primarily depend on triggers from audit events provided, these events can be delayed in large AWS environments, or by a flood of activity.
What are some of the positive impacts automated remediation tools?
- Increased efficiency: Can reduce the time and resources required to respond to security incidents, allowing security teams to focus on higher-value tasks.
- Improved collaboration: Can help break down silos between different teams, as it often requires cross-functional collaboration between security, operations, and development teams.
- Reduced burnout: By automating repetitive and time-consuming tasks, automated remediation can help reduce burnout among security people, who may otherwise be overwhelmed by the volume of security incidents they need to respond to manually.
- Skills development: As organizations adopt these tools and processes, security teams may need to develop new skills and competencies in areas such as automation, scripting, and orchestration, which can have positive impacts on employee development and job satisfaction.
- Cultural shift towards proactive security: They can help shift the culture of security within an organization from reactive to proactive, by enabling security teams to identify and remediate potential security risks before they become actual security incidents.
Summary
Overall, while automated security remediation can have some cultural and productivity impacts that need to be managed, it can also bring significant benefits to organizations by enabling more efficient, collaborative, and proactive security practices.
That said, automated security remediation really needs to be part of a three-pronged approach:
- Ensure people are working in cloud environments with only the privileges they require to do their work. There are of course exceptions to this, but they should be covered with a process which allows users to request more access when required.
- SCPs should be used to protect security and governance services, and implement core restrictions within a collection of AWS accounts, depending on your business.
- Automated security remediation should be used to cover all the edge cases, again this should be used only where necessary, and with the understanding it may take a period of time to fix.
One thing to note is we are working in an environment with a lot of smart and resourceful people, so organizations need to watch for situations complex workarounds evolve to mitigate ineffective or complex controls otherwise they may impact morale, onboarding of staff and overall success of a business.
Security works best when it balances threats and usability!
]]>One thing to note is in my day job I work on an Apple Mac, but my personal machine is a Linux laptop running PopOS. I find using Linux as a desktop works as most software I use is web based or supported on linux. I also use it for IoT development as pretty much all the tool chains I use supports it.
On a whole over the years I have moved to a more minimal setup, primarily to keep things simple, less is easier to maintain, easier to share, and more likely to be adopted by others.
The stack I work with professionally is pretty varied, but can be summarized as:
- Amazon Web Services (AWS), I work primarily this cloud platform in my day job
- Cloudformation, native AWS infrastructure deployment
- Go, great language for building tools, apis, and backend services
- Python, used for cloud orchestration, scripting and machine learning
- NodeJS often using Typescript, for frontend development
- Git, used for all things source code
CLI Tools
I primarily use zsh as my shell, sticking to a pretty minimal setup tools wise.
- Docker for containers, which I mainly use for testing.
- direnv which is used to change environment settings in projects.
- The Silver Searcher a faster search tool for the cli,
agis my goto for locating stuff in files when developing. - Git Hub CLI, makes working with GitHub from the CLI a dream.
- AWS CLI is used to write scripts and diagnosing what is up with my cloud.
- AWS SAM CLI for deploying cloudformation in a semi sane way.
- nvm, nodejs changes a lot so I often need a couple of versions installed to support both new and old software.
- Git Prompt for a dash more information in my shell about the current trees Git status.
- gnupg, which I mostly use for Signing of Git commits and software, and a bit of data encryption.
Most of my builds done using the good old Makefile so I always have make installed.
Editor
Currently I use vscode when developing, it is one of the first things I open each day. I was a vim user but moved to vscode as I prefer to use a more approachable editor, especially as I work with developers and “non tech” people and they find it less daunting to learn.
I am trying to help everyone code, so using an approachable editor is really helpful!
To support the stack I use the following plugins:
- Code Spell Checker, I really hate misspelling words in my code.
- EditorConfig for VS Code, handy way to keep things consistently formatted across editors when working in a team.
- GitLens — Git supercharged, helps me figure out what changed and who changed it without leaving my editor.
- Go, primary language I develop in.
- indent-rainbow, this addon keeps me sane when editing whitespace sensitive languages such as python and YAML!
- Python, tons of stuff uses this language so I always end up using it.
- vscode-cfn-lint, avoiding obvious errors and typos in my cloudformation templates saves a ton of time and frustration.
- TODO Highlight, I always try and add information and notes to my code, this helps highlight the important stuff.
- YAML, most of the tools I deploy with use it for configuration so I need a good linter.
- GitHub Theme, I use the dimmed dark mode which is really nice comfortable coding theme.
So why would you ever want to dive into AWS Billing data in the first place?
- It is pretty easy for both novices, and experience developers to rack up a sizable bill in AWS, part of the learning experience is figuring out how this happened.
- The billing data itself is available in parquet format, which is a great format to query and dig into with services such as Athena.
- This billing data is the only way of figuring out how much a specific AWS resource costs, this again is helpful for the learning experience.
- The Cost Explorer in AWS is great if you just want an overview, but having SQL access to the data is better for developers looking to dive a bit deeper.
- The billing service has a feature which records
created_byfor resources, this is only available in the CUR data. If you have already you can enable it via Cost Allocation Tags.
These points paired with the fact that a basic understanding of data wrangling in AWS is an invaluable skill to have in your repertoire.
Suggested CUR Solution
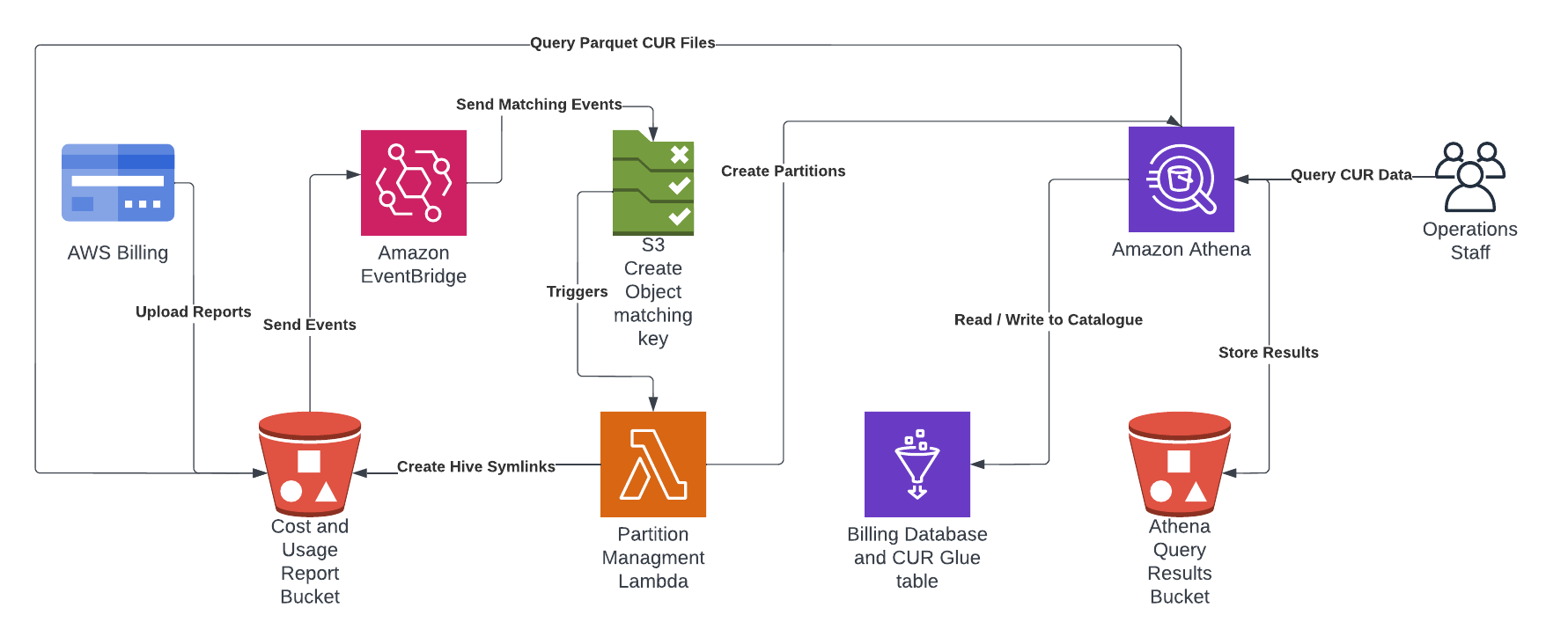
I have put together an automated solution which uses AWS CloudFormation to create a Cost and Usage Reports (CUR) in your billing account with a Glue Table enabling querying of the latest data for each month in Amazon Athena. This project is on github at https://github.com/wolfeidau/aws-billing-store, follow the README.md to get it setup.
In summary it deploys:
- Creates the CUR in the billing service and the bucket which receives the reports.
- Configures a Glue Database and Table for use by Athena.
- Deploys a Lambda function to manage the partitions using Amazon EventBridge S3 events.
Once deployed all you need to do is wait till AWS pushes the first report to the solution, this can take up to 8 hours in my experience, then you should be able to log into Athena and start querying the data.
One thing to note is designed to be a starting point, I have released it under Apache 2.0 license so your welcome to pull this solution apart and integrate it into your environment.
Next Steps
To test the solution you can start with a query which shows you AmazonS3 costs grouped by bucket name and aggregated using sum.
SELECT line_item_resource_id as bucket_name,
round(sum(line_item_blended_cost), 4) AS cost,
month
from "raw_cur_data"
WHERE year = '2022'
and month = '7'
AND line_item_product_code = 'AmazonS3'
GROUP BY line_item_resource_id,
month
ORDER BY cost DESC;
There are some great resources with other more advanced queries which provide insights from your CUR data, one of the best is Level 300: AWS CUR Query Library from the The Well-Architected Labs website.
The standout queries for me are:
- Amazon GuardDuty - This query provides daily unblended cost and usage information about Amazon GuardDuty Usage. The usage amount and cost will be summed.
- Amazon S3 - This query provides daily unblended cost and usage information for Amazon S3. The output will include detailed information about the resource id (bucket name), operation, and usage type. The usage amount and cost will be summed, and rows will be sorted by day (ascending), then cost (descending).
Cost Allocation Tags
The Cost Allocation Tags in billing allows you to record data which is included in the CUR. This is a great resource for attributing cost to a user, role or service, or alternatively a cloudformation stack.
I enable the following AWS tags for collection and inclusion in the CUR.
aws:cloudformation:stack-nameaws:createdBy
I also enable some of my own custom tags for collection and inclusion in the CUR.
applicationcomponentbranchenvironment
You can see how these are added in the https://github.com/wolfeidau/aws-billing-store project Makefile when the stacks are launched.
Case in point, the AWS CLI which a large number of engineers and developers rely on every day, the following command will create a bucket.
$ aws s3 mb s3://my-important-data
One would assume this commonly referenced example which is used in a lot of the resources provided by AWS would create a bucket following the best practices. But alas no…
The configuration which is considered best practice for security of an S3 bucket missing is:
- Enable Default Encryption
- Block Public access configuration
- Enforce encryption of data in transit (HTTPS)
Why is this a Problem?
I personally have a lot of experience teaching developers how to get started in AWS, and time and time again it is lax defaults which let this cohort down. Of course this happens a lot while they are just getting started.
Sure there are guard rails implemented using services such as AWS Security Hub, pointing out issues left right and center, but these typically identity problems which wouldn’t be there in the first place if the tools where providing better defaults.
Sure there is more advanced configuration but encryption and blocking public access by default seem like a good start, and would reduce the noise of these tools.
The key point here is it should be hard for new developers to avoid these recommended, and recognised best practices when creating an S3 bucket.
In addition to this, keeping up with the ever growing list of “best practice” configuration is really impacting both velocity and morale of both seasoned, and those new the platform. Providing some tools which help developers keep up, and provide some uplift when upgrading existing infrastructure would be a boon.
Now this is especially the case for developers building solutions using serverless as they tend to use more of the AWS native services, and in turn trigger more of these “guard rails”.
Lastly there are a lot of developers out there who just don’t have time to “harden” their environments, teams who have no choice but to ignore “best practices” and may benefit a lot from some uplift in this area.
What about Cloudformation?
To further demonstrate this issue this is s3 bucket creation in cloudformation, which is the baseline orchestration tool for building resources, provided free of charge by AWS. This is a very basic example, as seen in a lot of projects on GitHub, and the AWS cloudformation documentation.
MyDataBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: MyDataBucket
Now you could argue that cloudformation is doing exactly what you tell it to do, it is just a primitive layer which translates YAML or JSON into API calls to AWS, but I think again this is really letting developers down.
Again this is missing default encryption, and public access safe guards. Now in addition to this a lot of quality tools also recommend the following:
- Explicit deny of Delete* operations, good practice for systems of record
- Enable Versioning, optional but good practice for systems of record
- Enable object access logging, which is omitted it to keep the example brief
So this is a basic example with most of these options enabled, this is quite a lot to fill in for yourself.
MyDataBucket:
Type: AWS::S3::Bucket
DeletionPolicy: Retain
UpdateReplacePolicy: Retain
Properties:
BucketName: !Ref BucketName
BucketEncryption:
ServerSideEncryptionConfiguration:
- ServerSideEncryptionByDefault:
SSEAlgorithm: AES256
VersioningConfiguration:
Status: Enabled
PublicAccessBlockConfiguration:
BlockPublicAcls: True
BlockPublicPolicy: True
IgnorePublicAcls: True
RestrictPublicBuckets: True
MyDataBucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref MyDataBucket
PolicyDocument:
Id: AccessLogBucketPolicy
Version: "2012-10-17"
Statement:
- Sid: AllowSSLRequestsOnly
Action:
- s3:*
Effect: Deny
Resource:
- !Sub "arn:aws:s3:::${MyDataBucket}/*"
- !Sub "arn:aws:s3:::${MyDataBucket}"
Condition:
Bool:
"aws:SecureTransport": "false"
Principal: "*"
- Sid: Restrict Delete* Actions
Action: s3:Delete*
Effect: Deny
Principal: "*"
Resource: !Sub "arn:aws:s3:::${MyDataBucket}/*"
To do this with the AWS CLI in one command would require quite a few flags, and options, rather than including that here I will leave that exercise up to the reader.
Now some may say this is a great opportunity for consulting companies to endlessly uplift customer infrastructure. But this again begs the questions:
- Why is this the case for customers using the recommended tools?
- What about developers getting started on their first application?
- Wouldn’t be better to have these consultants building something new, rather than crafting reams of YAML?
Why Provide Resources which are Secure by Default?
So I have used S3 buckets as a very common example, but there is an ever growing list of services in the AWS that I think would benefit from better default configuration.
Just to summarise some of the points I have made above:
- It would make it harder for those new to the cloud to do the wrong thing when following examples.
- The cost of building and maintaining infrastructure would be reduced over time as safer defaults would remove the need for pages of code to deploy “secure” s3 buckets.
- For new and busy developers things would be mostly right from the beginning, and likewise update that baseline even just for new applications, leaving them more time to do the actual work they should be doing.
So anyone who is old enough to remember Sun Solaris will recall the “secure by default” effort launched with Solaris 10 around 2005, this also came with “self healing” (stretch goal for AWS?), so security issues around defaults is not a new problem, but has been addressed before!
Follow Up Q&A
I have added some of the questions I received while reviewing this article, with some answers I put together.
Will CDK help with this problem of defaults?
So as it stands now I don’t believe the default s3 bucket construct has any special default settings, there is certainly room for someone to make “secure” versions of the constructs but developers would need to search for them and that kind of misses the point of helping wider AWS user community.
Why don’t you just write your own CLI to create buckets?
This is a good suggestion, however I already have my fair share of side projects, if I was to do this it would need to be championed by a orginisation, and team that got value from the effort. But again, needing to tell every new engineer to ignore the default AWS CLI as it isn’t “secure” seems to be less than ideal, I really want everyone to be “secure”.
How did you come up with this topic?
Well I am currently working through “retrofitting” best practices (the latest ones) on a bunch of aws serverless stacks which I helped build a year or so ago, this is when I asked the question why am I searching then helping to document what is “baseline” configuration for s3 buckets?!
Won’t this make the tools more complicated adding all these best practices?
I think any uplift at all would be a bonus at the moment, I don’t think it would be wise to take on every best practice out there, but surely the 80/20 rule would apply here. Anything to reduce the amount of retro fitting we need to do would be a good thing in my view.
]]>To start out it is helpful to have an overview, this post and the associated talk Moving to event-driven architectures (SVS308-R1) are a good place to start.
Then for those that want to see some code, take a look at the analytics component in this project developed by the serverless team at AWS, there are tons of great infra examples in this project. Although the code is a bit complex there is a lot to garner even if your not a Java developer.
This project uses a great reusable component which takes a AWS DynamoDB stream and publishes it onto AWS Eventbridge, again if Java isn’t your language of choice there are still some gems in here, such as the logic used to retry submission of events to Eventbridge.
From the AWS Samples comes this project which is worth digging into, it has a bunch of simple examples with diagrams which are always a plus.
To enable some experimentation and development this CLI tool is pretty handy.
As I go I will add links and happy to take suggestions.
]]>When setting up an applications authentication I try to keep in mind a few goals:
- Keep my users data as safe as possible.
- Try and find something which is standards based, or supports integrating with standard protocols such as openid, oauth2 and SAML.
- Evaluate the authentication flows I need and avoid increasing scope and risk.
- Try to use a service to start with, or secondarily, an opensource project with a good security process and a healthy community.
- Limit any custom development to extensions, rather than throwing out the baby with the bath water.
As you can probably tell, my primary goal is to keep authentication out of my applications, I really don’t have the time or inclination to manage a handcrafted authentication solution.
What does AWS Cognito provide out of the box?
Lets look at what we get out of the box:
- Storing and protecting your users data with features such as Secure Remote Password Protocol (SRP).
- Signing up for an account with email / sms verification
- Signing in, optionally with Multi Factor Authentication (MFA)
- Password change and recovery
- A number of triggers which can be used to extend the product
What is great about Cognito?
Where AWS Cognito really shines is:
- Out of the box compliance to standards such as SOC and PCI
- Integration with a range of platform identity providers, such as Google, Apple and Amazon
- Support for integration with identity providers (IdPs) using OpenID and SAML.
- Really easy to integrate into your application using libraries such as AmplifyJS.
- AWS is managing it for a minimal cost
What is not so great about Cognito?
Where AWS Cognito can be a challenge for developers:
- Can be difficult to setup, and understand some of the settings which can only be updated during creation, changing these requires you to delete and recreate your pool.
- Per account quotas on API calls
- A lack of search
- No inbuilt to backup and restore the user data in your pool
So how do we address some of these challenges, while still getting the value provided and being able to capitalise on it’s security and compliance features.
What is the best way to setup Cognito?
To setup Cognito I typically use one of the many open source cloudformation templates on GitHub. I crafted this template some time ago cognito.yml, it supports login using email address, and domain white listing for sign ups.
As a follow on from this I built a serverless application serverless-cognito-auth which encapsulates a lot of the standard functionality I use in applications.
You can also use AWS Mobile Hub or AWS Amplify to bootstrap a Cognito pool for you.
Overall recommendations are:
- If your new to Cognito and want things to just work then I recommend trying AWS Amplify.
- If you are an old hand and just want Cognito the way you like it, then use one of the many prebuilt templates.
How do I avoid quota related issues?
Firstly I recommend familiarising yourself with the AWS Cognito Limits Page.
I haven’t seen an application hit request rate this more than a couple of times, and both those were related to UI bugs which continuously polled the Cognito API.
The one limit I have seen hit is the sign up emails per day limit, this can be a pain on launch days for apps, or when there is a spike in sign ups. If your planning to use Cognito in a startup you will need to integrate with SES.
How do I work around searching my user database?
Out of the box cognito will only allow you to list and filter users by a list of common attributes, this doesn’t include custom attributes, so if you add an attribute like customerId you won’t be able to find all users with a given value.
This limitation makes it difficult to replace an internal database driven authentication library just using the cognito service, so for this reason I recommend adding a DynamoDB table to your application and integrating this with cognito using lambda triggers to build your own global user store.
To simplify interacting with Cognito I wrote a CLI which provides some helpful commands to scan, filter, export and perform some common admin functions, you can find it at https://github.com/wolfeidau/cognito-cli.
How do I back up my user pool?
Backing up user accounts in any system is something you need to consider carefully as this information typically includes credentials as well as other sensitive data such as mobile number which is often used as a second factor for other services.
Currently Cognito doesn’t provide a simple way of exporting user data, the service does however have an import function which will import users in from a CSV file.
Note: AWS cognito doesn’t support export user passwords, these will need to be reset after restore.
For some examples of tooling see cognito-backup-restore.
Conclusion
If you really care about security and compliance then cognito is a great solution, it has some limitations, and gaps but these can be worked around if you want to focus your effort somewhere else.
Personally I think it is really important that as a developer I pick solutions which ensure my customers data is locked away as securely as possible, and ideally using a managed service.
You could totally roll your own authentication solution, and manage all the patching and challenges which go with that but that makes very little sense when you should probably be solving the original problem you had.
Authentication is a yak I am willing to let someone else shave manage, and so should you, if not for your own sanity, then that of your users.
Lastly if your building out a web application use amplify-js, this library makes it so easy to add Cognito authentication to your web application. I used it on cognito-vue-bootstrap which you can also check out.
]]>The AWS Cloud Development Kit (AWS CDK) is an open-source software development framework to define cloud infrastructure in code and provision it through AWS CloudFormation.
Before I go recommending this new project to anyone I most certainly need to road test it myself. This post provides a bit of background on where I work, and why I am looking into CDK, and what I love to see in the future.
Background
I have been building applications in Amazon Web Services (AWS) for a number of years using as many of the services as possible to keep things lean and online, that said it doesn’t come without some overhead and many lessons learned. While working in AWS I have always chosen to stick to native tools, such as Cloudformation, augmented by a range of deployment tools, this has means I get all the power with the inherent complexity, which grows every AWS reinvent conference.
Hiring into an organization which works very closely with AWS comes with some challenges. New hires will typically find themselves learning a lot of new services, while also grappling with Cloudformation. This can really impact a new team members productivity, and more importantly their confidence, especially when the first few PR reviews call out security issues, and subtle pitfalls around resource naming the examples they build find on the internet.
For this reason I have been looking at ways to reduce risk of issues in production without falling into the trap of isolating infrastructure development to a small number of “experts”, this is why CDK popped up on my radar. It promises to allow developers to manage to assemble stacks using reusable patterns either developed by AWS, or internally using code not YAML, which in my view is a big plus.
In short I care more about people than I care about technology, I want it to empower those who use it, not hold them back.
Road Testing
As I was starting to road test CDK I was fortunate enough to catch up with some of my peers from AWS Partner Community and get some good tips and anecdotes on what to dig into. Based on this I have put together some points, these are grouped into the good, the bad and the ugly.
The Good
- CDK enables developers to describe their infrastructure in code using an object model, then lets them synthesize it into Cloudformation templates.
- VPC resources can be “connected” to each other, this automatically creates the required security groups, and entries in them.
- Accessing a secret value will also update IAM policies, updating roles with the required policy changes.
- CDK automatically creates policies that narrow access down to the least privileges required to operate based on your model. This is a boon as because it is one of the most complex and time consuming aspects of crafting a Cloudformation template.
- The Cloudformation produced by CDK has sane defaults such as:
- Enables deletion protection for Relational Database Service (RDS) instances to avoid accidental deletion during stack updates.
- Enables orphaning of S3 buckets which leaves them behind when a stack update occurs, therefore avoiding deletion of all your data when messing with configuration of a resource in your stack.
- Includes patterns which incorporate a range of best practices, helpers and security enhancements.
- An example of this is the
LoadBalancedFargateServicewhich can deploy a build and deploy a local service using aDockerfilewithout ever having to delve into the finer points of Elastic Container Registry (ECR), Elastic Container Service (ECS) or Application Load balancers (ALB).
- An example of this is the
- Personally I feel a lot more productive with CDK, I am writing less code and producing more secure, consistent infrastructure.
The Bad
- Although amazing, the patterns feel like black boxes, there is no way to click through into the source code of an underlying pattern and dig into how it works.
- Personally I think these should illustrate how amazing this model is, and act as a spring board into developing your own modules, currently it feels like a black box.
- Yes I can clone and dig into repositories but the whole point of this is to be here for a good time, not a long time.
- It is really difficult to lock down the version of CDK in your NodeJS projects once a new release has come out. If there are changes I want to skip then I have to get a lock file from an older project, which breaks as soon as I add other CDK modules.
- This is a less than ideal user experience for teams who aren’t moving as fast as the CDK development team.
- Note work is happening to sort out semver usage in cdk packages issue #3711 which is great!
- The whole multi language, cross compiled thing seems very limited at the moment, especially around the lack of support for sharing modules developed in languages other than Typescript.
- For more information on how CDK deliver polyglot libraries checkout the aws/jsii project on GitHub
- Some background on Python experience requiring NodeJS tooling.
The Ugly
- In the current CDK I am encouraged, if not required to synthesize my templates in every AWS account I use, this is a big red flag for me.
- If team member updates a service deployed a couple of month after it’s initial release there is NO guarantee the same code Cloudformation will be generated. To cover this operators will need to “stash” or archive templates for every account, before every deploy.
- The NPM locking issues around pinning upgrades really restricts your power to ensure managed changes to Cloudformation.
This lack of reusable, easily reproducible artifacts is a bit of a show stopper for me, given the number of times I have been let down by tools which generate Cloudformation, I am loath to leap back into it for a production environment.
Summary
In short I will not be putting CDK between me and a production environment until some of the reproducible challenges are addressed. Like many of my peers, I have always advocated for solid, reproducible infrastructure tooling that is as simple as possible to recover and rollback.
That said I will most definitely be using CDK to quickly generate Cloudformation, especially generating IAM policies with least privileged, and harvesting some of the great ideas, and tricks from the patterns.
I would recommend using Typescript to develop CDK scripts, this will ensure you get the most reuse and enable harvesting directly from the CDK patterns!
Contributors
Thanks to Ashish Rajan @hashishrajan and Rowan Udell @elrowan for reviewing this post, Ian Mckay @iann0036 for starting a impromptu CDK discussion in Seattle and Aaron Walker @aaronwalker for being a great sounding board and walking me through some of his experience with CDK.
Example Project
My current work with CDK is mainly focused on providing infrastructure to a container based application called exitus which is hosted on GitHub with the CDK infra code exitus.ts. Ian Mckay
]]>- complex customer on boarding processes jobs which provision resources then send a welcome email
- billing jobs where you may need wait for payment authorisation
- provisioning users and setup of any resources each user may need
pipeline
In software engineering, a pipeline consists of a chain of processing elements (processes, threads, coroutines, functions, etc.), arranged so that the output of each element is the input of the next; the name is by analogy to a physical pipeline.
The term pipeline is used a lot in building of software, but can refer to any chain of tasks.
Over the last couple of years I have used Step Functions in a range of business applications, initially with mixed success due to service limitations and trying to fit complex “new requirements” into the model. Over time this changed as I better understand where step functions start and end.
I have put together a list of tips and recommendations for those using step functions.
Start Small
Practice with a few small workflows to get started, avoid building a Rube Goldberg machine. This means starting with something you already know and refactoring it to incorporate a step function, get used to tracing issues and make sure you have all the tools and experience to operate a serverless application.
Track Executions
Include a correlation id in all flow execution payloads, this could be seeded from Amazon correlation id included with all API gateway calls. This correlation id may be used for reruns of the state machine so don’t use it as the execution name.
Naming Things
Execution name should include some hints to why the flow is running, with a unique id or timestamp appended.
Step names should clearly indicate what this step does as this will enable devs or operations identify where errors or mistakes are occurring.
Exception Handling
When using Lambda functions make sure you use an exception tracker such as bugsnag or sentry to make fault finding easier. This allows you to track issues over time and avoids sifting through logs looking for errors.
Use the retry backoff built into each step to make your flows more robust.
Logging
Emit structured logs with key start and end information and use cloudwatch to search capture metrics, and trigger alerts based on them.
Infrastructure Automation
As an infrastructure engineer I use Step Functions to build and deploy a number of different applications, this is mainly where:
- The task happens often
- Someone owns the infrastructure and integration is required to orchestrate with external systems
- There are a lot of “services” of a similar shape which need to be deployed the same way
When using cloudformation make sure you use change sets, this will allow you to:
- Print a nice list of what will change before performing a change or create.
- Rollback in a nicer way
When cloudformation changes fail try to collect the tail of the execution events to simplify fault finding.
When designing flows make sure they aren’t too generic, their structure should reflect what your automating, similar to an ansible playbook.
Build up a task modules to interface with cloudformation, and whenever possible just use that with custom cloud formation tasks.
Build up a library of common tasks, which can be used by lambdas. Test these thoroughly using unit and integration tests.
Use common sense when managing common code, don’t dump everything in there, keep to just the most important tasks. This just results in a teams or systems having a massive boat anchor holding back, and contributing to the fragility of the entire platform.
]]>In the serverless space AWS Step Functions play a similar role to projects such as delayed job or resque in ruby, celery in python, but with the following differences:
- Built on a flexible flow definition language called Amazon States Language which is written in JSON
- Powered by lambda, with native integration to SNS, SQS, Kinesis and API Gateway
- Fully Managed by AWS
Step Functions?
AWS Step Functions provides a way of executing flows you have defined, and provides a visual representation, like a CI pipeline, showing the current state of the execution.
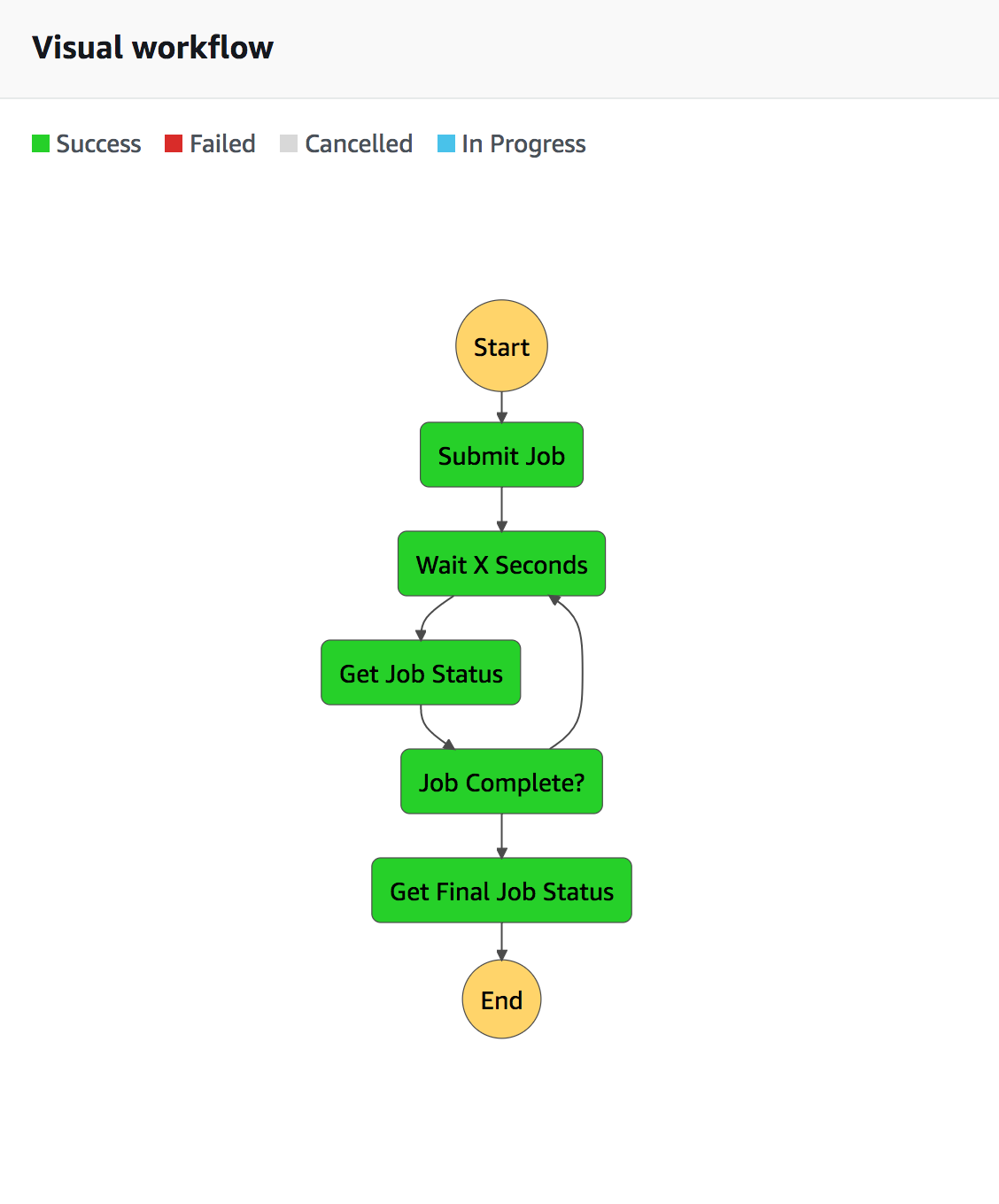
A simple task management example which polls the status of a task, and reports completion status can be seen as follows:
Why Step Functions?
So this is great but why should we decompose our workflows into functions and glue them together using a managed service?
There are a number of things to be gained by moving to Step Functions:
- Testing, you will be able to test each element in the chain and make sure it performs it’s discreet task.
- Decoupling, you will have broken things down into pieces of code which can be refactored, or replaced independent of each other.
- Monitoring, given the visual nature of these pipelines you will be able to zero in on failures faster.
Step Functions aren’t the answer to every problem, but for multi step, long running jobs they are a great solution, if your fluent in the AWS ecosystem.
]]>In this post I will show how to use the DeepRacer for ROS development.
So why would I use DeepRacer for ROS development?
- Intel based so very easy to build and upload binaries / projects.
- It works out of the box and is very well designed.
- It will retail for 249 USD in march, given it’s high quality components it will be very useful.
- It is based on Ubuntu 16.04.3, and ROS Kinetic which is a good solid starting point for ROS Development.
Below is a picture the RC car chassis which is a really nice size.

Logging into your DeepRacer
Logging into the DeepRacer for the first time is very similar to the DeepLens product, plug the compute module into a monitor using a HDMI cable and a USB Keyboard and mouse, then reset the users password to some value which satisfies the complexity requirements. I believe it is at least 8 characters, one upper, lower, number and a symbol.
Note: The username is deepracer.
Preparing your DeepRacer
In my case I also disabled x11, and enabled SSH.
To permit ssh through the firewall configured on the device I ran, the server was already installed and started.
sudo ufw allow ssh
To disable the desktop environment on the next restart run the following.
sudo systemctl disable lightdm.service
Note: I did this while the screen and keyboard where plugged in, then tested I could ssh to the DeepRacer from my laptop before restarting.
Now that you have ssh’d into the DeepRacer using your login details, and the TAG_HOSTNAME is on a tag on the bottom of the car.
ssh deepracer@TAG_HOSTNAME
Before you starting to mess around on the host you probably want to disable ufw to enable access to all the services from your laptop/desktop.
sudo ufw disable
Once you have disabled the firewall your should be able to access the video stream from ROS web_video_server using http://TAG_HOSTNAME.local:8080/stream_viewer?topic=/video_mjpeg where the TAG_HOSTNAME is on a tag on the bottom of the car. For more information on this service see http://wiki.ros.org/web_video_server.
Disable ROS Services
We are going to disable services which relate to the DeepRacer service, including the updates service so we can just use the control and media systems.
This is as simple as replacing /opt/aws/deepracer/share/deepracer_launcher/launch/deepracer.launch with content as follows, this simply comments out some of the AWS supplied services.
<?xml version="1.0"?>
<launch>
<node pkg="web_video_server" type="web_video_server" name="web_video_server">
<param name="ros_threads" value="1" />
</node>
<node name="servo_node" pkg="servo_pkg" type="servo_node" respawn="true" />
<node name="media_engine" pkg="media_pkg" type="media_node" respawn="true" />
<!-- <node name="inference_engine" pkg="inference_pkg" type="inference_node" respawn="true" output="screen"/> -->
<!-- <node name="inference_probability" pkg="inference_pkg" type="inference_probability.py" respawn="true"/> -->
<!-- <node name="model_optimizer" pkg="inference_pkg" type="model_optimizer_node.py" respawn="true" /> -->
<node name="control_node" pkg="ctrl_pkg" type="ctrl_node" respawn="true" />
<!-- <node name="navigation_node" pkg="ctrl_pkg" type="navigation_node.py" respawn="true" /> -->
<!-- <node name="software_update" pkg="software_update_pkg" type="software_update_process.py" respawn="true" /> -->
<!-- <node name="webserver" pkg="webserver_pkg" type="webserver.py" respawn="true" /> -->
</launch>
Now restart the DeepRacer service.
$ sudo systemctl restart deepracer-core.service
Is this thing on?
To test whether or not we can still drive the DeepRacer around, we will explore then interface with the control node provided.
Now we load the ROS environment, using the AWS setup.bash, this will populate variables holding names and paths for services, if you have never used ROS before you may want to run through some of the Tutorials.
$ source /opt/aws/deepracer/setup.bash
Now we should just have the services we need to start working with ROS.
$ rosnode list
/control_node
/media_engine
/rosout
/servo_node
/web_video_server
Lets look at the topics which are now accepting messages.
$ rostopic list
/auto_drive
/calibration_drive
/manual_drive
/rosout
/rosout_agg
/video_mjpeg
Now we are interested in /manual_drive to test out the throttle and steering.
$ rostopic info /manual_drive
Type: ctrl_pkg/ServoCtrlMsg
Publishers: None
Subscribers:
* /control_node (http://amss-n4lp:37837/)
So we need to post a message to this topic, but we need to know the format so lets print it’s structure.
$ rosmsg info ctrl_pkg/ServoCtrlMsg
float32 angle
float32 throttle
Now while the DeepRacer is off my desk, to stop it racing off, I run the following command which should trigger a throttle change. Note that the limit for this value is 0.7 by default, and 0 will stop it.
rostopic pub -1 /manual_drive ctrl_pkg/ServoCtrlMsg -- 0 0.3
Now we can stop the throttle by running.
rostopic pub -1 /manual_drive ctrl_pkg/ServoCtrlMsg -- 0 0
Likewise we can turn the DeepRacer to the left using the first value.
rostopic pub -1 /manual_drive ctrl_pkg/ServoCtrlMsg -- 0.9 0
And to the right.
rostopic pub -1 /manual_drive ctrl_pkg/ServoCtrlMsg -- -0.9 0
Then back to the center.
rostopic pub -1 /manual_drive ctrl_pkg/ServoCtrlMsg -- 0 0
I am really impressed with the DeepRacer so far, it is a great platform to start working with ROS at a great price, hopefully it spurs a whole raft of great robotics projects in the future. I would also love to see more detail, and hopefully source code for the services in this product as they seem to be really well thought out and could most certainly provide a spring board for future innovation.
In my next post we will write a ROS node which will use these services to drive the DeepRacer.
]]>This post will detail how I configured Keycloak with AWS SAML federation.
To demonstrate Keycloak I have setup a docker-compose project which can be cloned from https://github.com/wolfeidau/keycloak-docker-compose.
Assuming you have docker for mac installed you should be able to navigate to the project then run.
docker-compose up -d
Then to ensure it is all working you should be able to navigate to http://0.0.0.0:18080/auth/admin/master/console/#/realms/master.
Setup of the AWS SAML Client
To simplify the automated setup we can export a client configuration file containing the AWS SAML configuration, in my case I did this in the master realm then exported it.
First thing you need to do is download https://signin.aws.amazon.com/static/saml-metadata.xml, just put it in your Downloads folder.
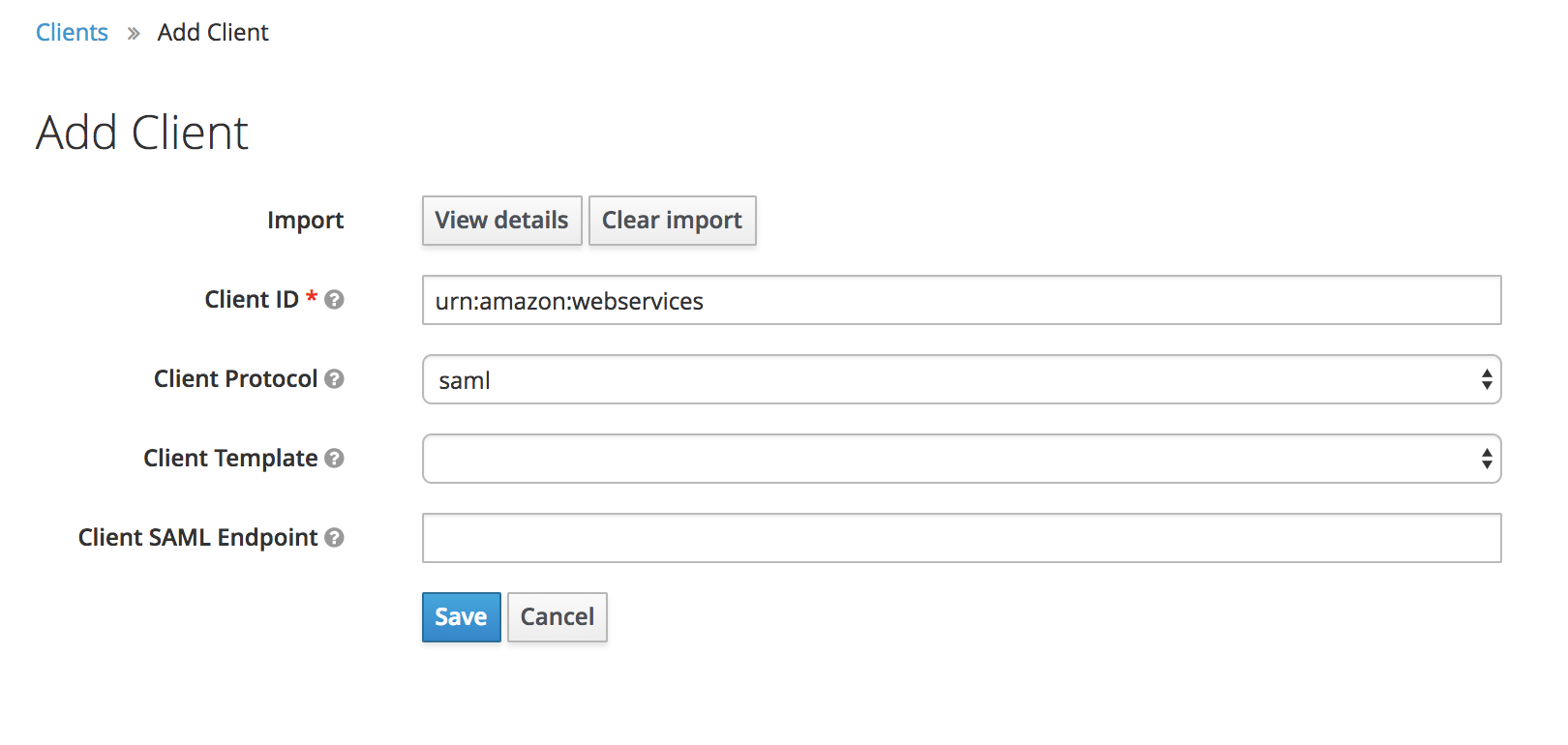
Once you login navigate to clients http://0.0.0.0:18080/auth/admin/master/console/#/realms/master/clients then hit the create button and import the saml-metadata.xml file, then hit save.
Now configure:
- IDP Initiated SSO URL Name to
amazon-aws - Base URL to
/auth/realms/wolfeidau/protocol/saml/clients/amazon-aws
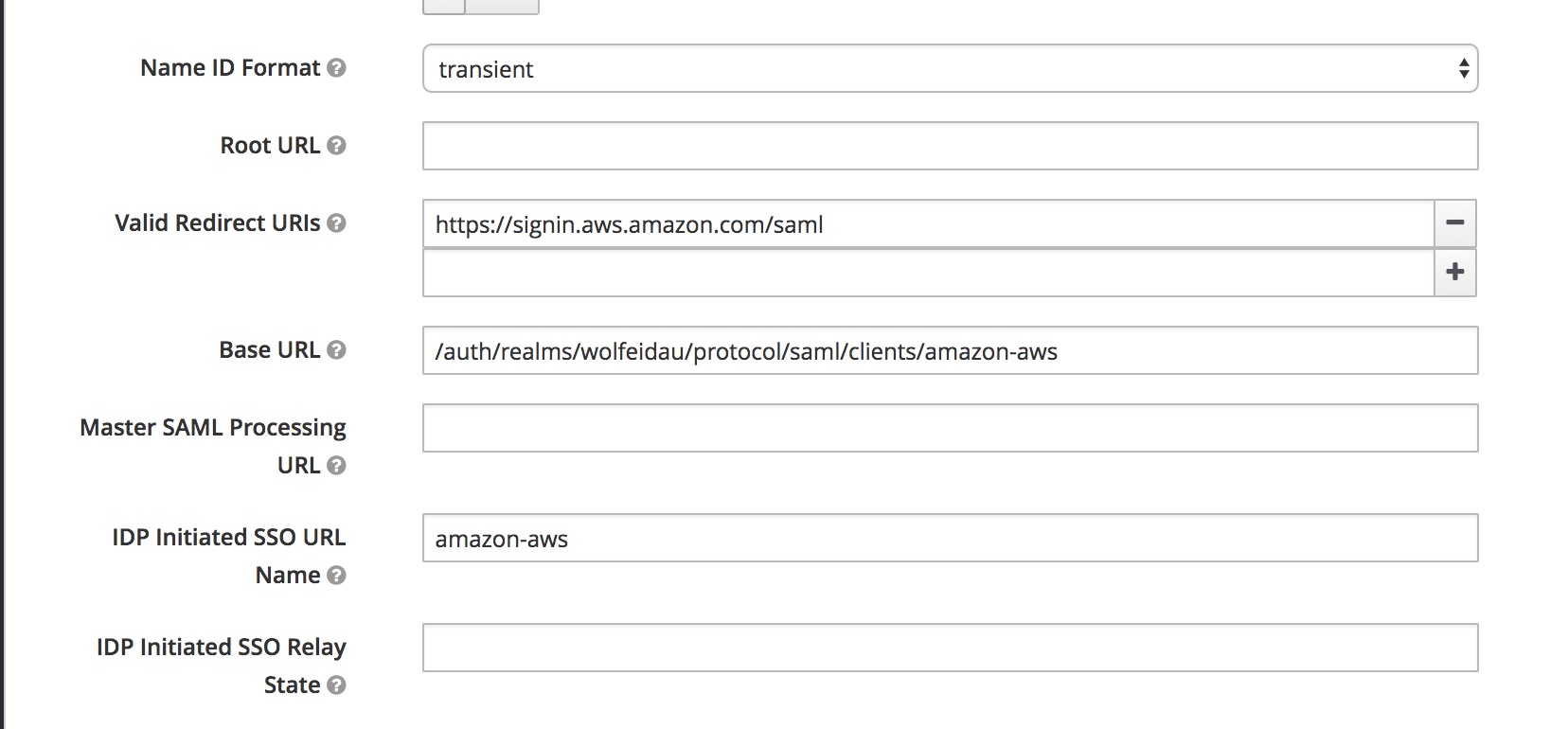
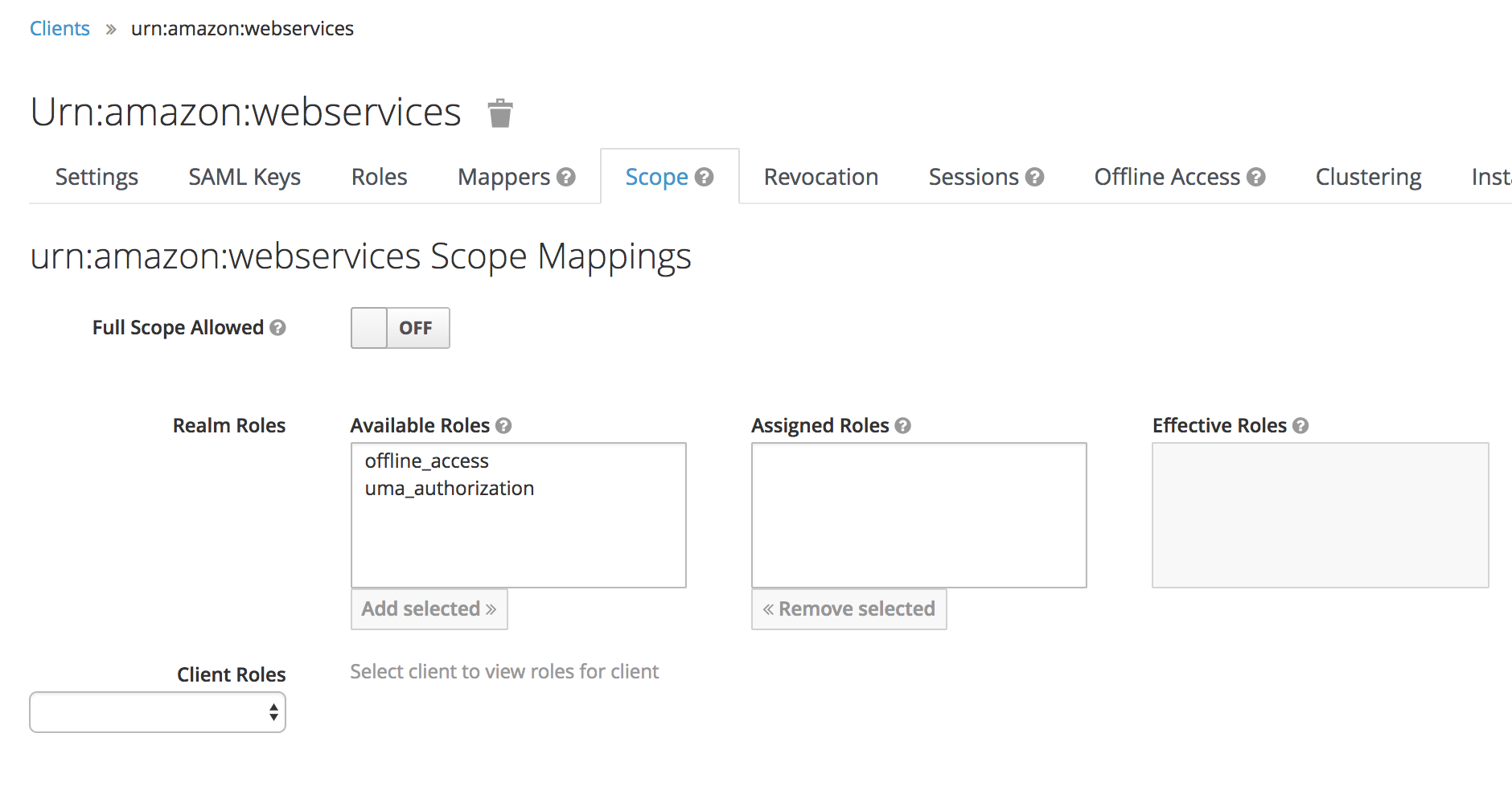
Lastly under the Scope tab disable Full Scope Allowed, this will ensure we only pass through the roles configured in our client to AWS.
Now you can navigate back to http://0.0.0.0:18080/auth/admin/master/console/#/realms/master/clients and hit the export button next to the aws client.
Keycloak Setup Using Admin CLI
As a big proponent of automation I really wanted to illustrate, and indeed learn how to automate setup of keycloak, hence the CLI approach.
To get the tools we need for this guide download keycloak from Keycloak Downloads and extract this to say $HOME/Development/keycloak then add $HOME/Development/keycloak/bin to your $PATH as per Keycloak administration CLI docs.
export PATH=$PATH:$HOME/Development/keycloak/bin
Note: Commands which create new objects generate a unique GUID which looks like 6c684579-51a1-4bdf-a694-d641199874d8, you will need to adjust those values in the subsequent commands.
Now we can use the administration CLI program to configure our keycloak service.
To test it out and configure your account locally.
kcadm.sh config credentials --server http://0.0.0.0:18080/auth --realm master --user admin
Create a realm, in my case I am naming this wolfeidau.
$ kcadm.sh create realms -s realm=wolfeidau -s enabled=true
Import the keycloak client for AWS and add it to the wolfeidau realm we created, the JSON file is in the keycloak-docker-compose project.
$ kcadm.sh create clients -r wolfeidau -s clientId="urn:amazon:webservices" -s enabled=true -f urn-amazon-webservices.json
Created new client with id '6c684579-51a1-4bdf-a694-d641199874d8'
Create our AWS role under the AWS client, note this is an example name you will need to replace 123456789012 with your account id.
kcadm.sh create clients/6c684579-51a1-4bdf-a694-d641199874d8/roles -r wolfeidau -s 'name=arn:aws:iam::123456789012:role/wolfeidau-admin,arn:aws:iam::123456789012:saml-provider/docker-keycloak' -s 'description=AWS Administration Access'
Created new role with id 'docker-keycloak'
Create a group to grant AWS administration access.
$ kcadm.sh create groups -r wolfeidau -s name=aws-admins
Created new group with id 'dd02ed86-dd49-47c6-bd8a-5f74844b56d0'
Add a role to the group, note this is an example name you will need to replace 123456789012 with your account id.
$ kcadm.sh add-roles -r wolfeidau --gname 'aws-admins' --cclientid 'urn:amazon:webservices' --rolename 'arn:aws:iam::123456789012:role/wolfeidau-admin,arn:aws:iam::123456789012:saml-provider/docker-keycloak'
Create a user for testing.
$ kcadm.sh create users -r wolfeidau -s username=wolfeidau -s email=mark@wolfe.id.au -s enabled=true
Created new user with id 'eb02cbfd-fa9c-4094-a437-3a218be53fe9'
Reset the users password and require update on login.
$ kcadm.sh update users/eb02cbfd-fa9c-4094-a437-3a218be53fe9/reset-password -r wolfeidau -s type=password -s value=NEWPASSWORD -s temporary=true -n
Add the user to our AWS administration group.
$ kcadm.sh update users/eb02cbfd-fa9c-4094-a437-3a218be53fe9/groups/dd02ed86-dd49-47c6-bd8a-5f74844b56d0 -r wolfeidau -s realm=wolfeidau -s userId=eb02cbfd-fa9c-4094-a437-3a218be53fe9 -s groupId=dd02ed86-dd49-47c6-bd8a-5f74844b56d0 -n
Export the metadata file required by AWS to setup the SAML provider.
$ kcadm.sh get -r wolfeidau clients/6c684579-51a1-4bdf-a694-d641199874d8/installation/providers/saml-idp-descriptor > client-tailored-saml-idp-metadata.xml
AWS Setup
Create the AWS SAML Provider in your account using the metadata file exported from keycloak.
aws iam create-saml-provider --saml-metadata-document file://client-tailored-saml-idp-metadata.xml --name docker-keycloak
Deploy the cloudformation template supplied in the keycloak-docker-compose project, this contains the SAML SSO IAM roles and saves clicking around in the UI.
aws cloudformation create-stack --capabilities CAPABILITY_IAM --stack-name sso-roles --template-body file://sso-roles-cfn.yaml
Note: You can just create the saml provider and launch the cloudformation from the AWS console.
Logging Into AWS
Now you should be ready to log into AWS using keycloak using the link http://0.0.0.0:18080/auth/realms/wolfeidau/protocol/saml/clients/amazon-aws.
Command Line SAML Authentication
To enable the use of SAML by command line tools such as ansible and the AWS CLI my colleagues and I developed saml2aws.
References
]]>Why DynamoDB?
Some of the advantages DynamoDB offers:
- A Key/Value model where the values are any number of fields
- Simplified data access
- Low operational overhead
- Cost, a well tuned DynamoDB costs a few dollars a month to operate
As a developer getting starting with DynamoDB you need to know about:
- Eventual consistency, this is integral to how DynamoDB achieves it’s cost, resilience and scalability. Simple things such as writing a record, then retrieving it straight afterwards require some logic to cope with records which aren’t visible yet.
- Performing
select * from Tableis not recommended when working with DynamoDB, this will trigger scan operations which are less efficient than other operations in DynamoDB. It should be only used on small tables.
Using any key/value store can be tricky at first, especially if you’re used to relational databases. I have put together a list of recommendations and tips which will hopefully help those starting out with this product.
Retries
When you insert data into DynamoDB not every shard will immediately see your data, an attempt to read the data from the table may not get the value your looking for. If your inserting a new row, then attempting to read immediately afterwards you may get an empty response.
To mitigate this you will need to implement retries, ideally with a back off to avoid exhausting your provisioned throughput.
Global secondary indexes (GSIs) further complicate this, as these are also updated eventually, in our experience even more eventually than the base table. Again be aware when inserting rows you want to access straight afterwards you may need to check if a row is present in the index with a similar retry.
Data Modelling
The first big thing you need to understand is that DynamoDB doesn’t have relationships, in most cases it will be better to start by storing related data denormalised in a given record using the document feature of the client APIs. The reason we do this is it can be difficult keeping related data across tables in sync.
I recommend keeping everything in a single record for as long as you can.
Pagination
Although most of the clients provided by amazon have a concept of paging built in, this is really forward only, which makes building a classic paginated list quite a bit harder. This is best illustrated with some excerpts from the DynamoDB API.
Firstly QueryInput from the golang AWS SDK we have the ability to pass in an ExclusiveStartKey.
type QueryInput struct {
...
// The primary key of the first item that this operation will evaluate. Use
// the value that was returned for LastEvaluatedKey in the previous operation.
//
// The data type for ExclusiveStartKey must be String, Number or Binary. No
// set data types are allowed.
ExclusiveStartKey map[string]*AttributeValue `type:"map"`
...
}
And in the QueryOutput we have the LastEvaluatedKey.
type QueryOutput struct {
...
// The primary key of the item where the operation stopped, inclusive of the
// previous result set. Use this value to start a new operation, excluding this
// value in the new request.
//
// If LastEvaluatedKey is empty, then the "last page" of results has been processed
// and there is no more data to be retrieved.
//
// If LastEvaluatedKey is not empty, it does not necessarily mean that there
// is more data in the result set. The only way to know when you have reached
// the end of the result set is when LastEvaluatedKey is empty.
LastEvaluatedKey map[string]*AttributeValue `type:"map"`
...
}
Given all we have are some keys, which may or may not be deleted it is very difficult to build a classic paged view.
So it has become clear to me we need to embrace a new strategy for displaying pages of results, luckily lots of others have run into this issue and the common pattern is to:
- Use infinite scrolling, similar to twitter and other social media sites.
- Maintain the state in the client with a cache of pages which have previously been loaded.
For more information on this see The End of Pagination.
Sorting
Just a small note on sorting, in more complicated tables you will need to add indexes purely to sort data in a specific way.
Also within the AWS api sorting uses the rather interestingly named ScanIndexForward.
// If ScanIndexForward is true, DynamoDB returns the results in the order in
// which they are stored (by sort key value). This is the default behavior.
// If ScanIndexForward is false, DynamoDB reads the results in reverse order
// by sort key value, and then returns the results to the client.
ScanIndexForward *bool `type:"boolean"`
You are not alone
These challenges presented by DynamoDB not unique, NoSQL databases such as Riak, and Cassandra, share some of the same limitations, again to enable resilience and scalability. When searching for ideas, suggestions or strategies to deal with it you may find answers around these open source projects.
In Closing
I think it is important to note that learning DynamoDB will broaden your horizons, and in some ways change the way you look at persistence, this in my view is a good thing.
]]>